
What is BeeOND?
BeeOND stands for BeeGFS on Demand, and is a complementary product to BeeGFS but can be used with other file systems as well. It is typically used to aggregate the performance and capacity of internal SSDs or hard disks in compute nodes for the duration of a compute job. This provides additional performance and a very elegant way of burst buffering. The way it works is to create one or multiple instances of BeeGFS on these compute nodes that can be created and destroyed “on-demand.”
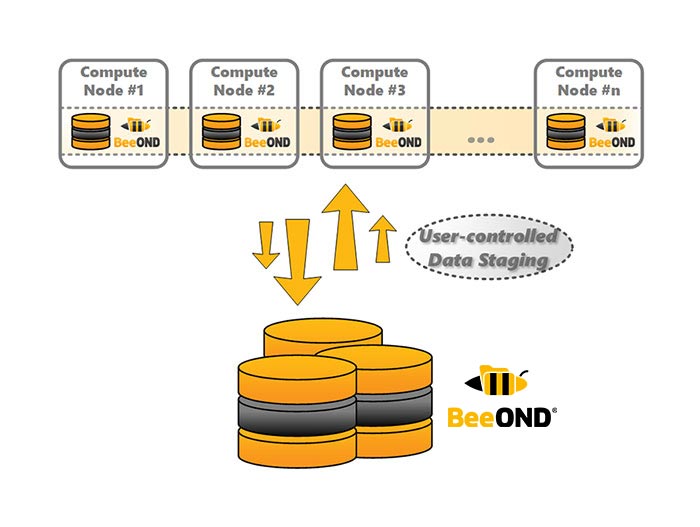
Why use BeeOND?
Modern compute nodes are often rich in SSDs and NVMe that are under utilized. By grouping unused high-speed resources together, a space is created where users can process some or all of their data much faster than on the standard hard disk based file system.
The main advantages of the typical BeeOND use-case on compute nodes are:
- A very easy way to remove I/O load and possibly nasty I/O patterns from your persistent global file system. Temporary data created during the job runtime will never need to be moved to your global persistent file system, anyways. But even the data that should be preserved after the job end might be better stored to a BeeOND instance initially and then at the end can be copied to the persistent global storage completely sequentially in large chunks for maximum bandwidth.
- Applications that run on BeeOND do not “disturb” other users of the global parallel file system and in turn also got the performance of the BeeOND drives exclusively for themselfes without any influence by other users.
- Applications can complete faster, because with BeeOND, they can be running on SSDs (or maybe even a RAM-disk), while they might only be running on spinning disks on your normal persistent global file system. Combining the SSDs of multiple compute nodes not only gets you to high bandwith easily, it also gets you to a system that can handle very high IOPS.
- BeeOND does not add any costs for new servers, because you are simply using the compute nodes that you already have.
- You are turning the internal compute node drives, which might otherwise be useless for many distributed applications, into a shared parallel file system, which can easily be used for distributed applications.
- You get an easy chance to benefit from BeeGFS, even though your persistent global file system might not be based on BeeGFS.
Get the most out of your SSDs
BeeOND uses existing NVMes and SSDs in the system, even space from SSDs shared with the OS. Many competitive burst buffer solutions require purchasing a new layer of expensive hardware, but BeeOND uses resources that already exist.
Enterprise Level Support
Pacific Teck is the official ThinkParQ Platinum Partner in Asia. Installation & Support is offered entirely by Pacific Teck and through our partner SIs. We have experience with the largest sites in Asia, and work back to back with ThinkParQ for source code level fixes. We recommend pairing with enterprise supported Altair Grid Engine.
Minimize I/O Problems
A very easy way to remove I/O load and possibly nasty I/O patterns from your persistent global file system. Temporary data created during the job runtime will never need to be moved to your global persistent file system, anyways. But even the data that should be preserved after the job end might be better stored to a BeeOND instance initially and then at the end can be copied to the persistent global storage completely sequentially in large chunks for maximum bandwidth.
Maximize IOPS
Applications can complete faster, because with BeeOND, they can be running on SSDs (or maybe even a RAM-disk), while they might only be running on spinning disks on your normal persistent global file system. Combining the SSDs of multiple compute nodes not only gets you to high bandwidth easily, it also gets you to a system that can handle very high IOPS.
Use Case
Machine Learning
Machine learning environments are often rich in NVMe resources for BeeOND to utilize. In Japan, Altair Grid Engine and BeeGFS/BeeOND are integrated at TiTech (540 Nodes with 4 P100 and 4 OPA HFIs per node ) and ABCI (1088 Nodes with 4 V100 and 2 EDR ports per node). Altair Grid Engine kicks off BeeOND and tells it how many NVMe to use, when to use it, and what to do after the job finishes. This is really an on demand burst buffer using the NVMe contained in compute nodes.
Scientific Computing
BeeOND help scientific clusters around the world achieve burst buffer level performance increases without breaking the budget. Together with Altair Grid Engine, this rich resource using existing hardware can be fairly shared among groups and users.
Benchmark and others
- 140 GB Per Second with BeeGFS and Oracle Cloud / Oracle Cloud Infrastructure
- Azure Reports 1 TB/s Cloud Parallel Filesystem with BeeGFS
- Tuning BeeGFS and BeeOND on Azure for specific I/O patterns
Case studies
- Benchmark of ABCI / AIST – Japan
- ABCI / AIST – Japan
- TSUBAME3.0 / Titech – Japan
- NARO – Japan
- Nagoya University – Japan
- Oakbridge-CX (FUJITSU PRIMERGY) / iTC – Japan
- A certain Japanese automobile parts manufacturer / for automatic driving – Japan
- National Taiwan University – Taiwan
- Academia Sinica Institute for Atomic and Molecular Biology – Taiwan
- A certain plastic molding maker / CAE – Taiwan
Documents
Contact
We can customize it to your needs. Please feel free to contact us regarding system configuration.
For any inquiries, please contact us via email at info@pacificteck.com .