2022年2月2日
ABCI / 産総研(AIST)

ABCIについて
日本の産業技術総合研究所(AIST)によって運用されているAIブリッジングクラウドインフラストラクチャ(ABCI)スーパーコンピュータは、いくつかの理由で注目に値します。 2018年6月のトップ500(#5)およびグリーン500(#8)リストの両方でトップ10ランキングを達成しました。 ABCIは高度なエネルギー効率を維持し、AIとディープラーニングを念頭に置いて構築された新しい種類のスーパーコンピュータです。

プロジェクト背景
ABCIの取り組みは、TSUBAME3.0スーパーコンピュータ(2018年6月Green500リスト6位)を構築して得た経験を基にしており、Altair Grid Engineで実行されています。理研RAIDENスーパーコンピュータ(2018年6月Green500リスト10位)と同様に、ABCIは最新のNVIDIA Tesla V100(Volta)GPUを使用します。ディープラーニングワークロードを大規模に実行および管理するには、高度なGPU対応のワークロード管理が必要です。
ABCIスーパーコンピュータは、301,680コア、476TBのメモリ、SSDストレージ全体に分散された約24PBのストレージ、および並列ファイルシステムを備えています。システムは1,088のInfiniband接続サーバーで構成され、各サーバーはデュアルIntel Xeon Gold 6148 CPU(Skylake)と4 x NVIDIA Tesla v100 GPU(Volta)を備え、それぞれが640 Tensorコアを備えています。 GPU間の通信は、NVIDIAのNVLinkによって促進され、PCIe Gen 3接続の最大10倍の帯域幅を提供します。
単一のGPUで分離されたディープラーニングアプリケーションを実行する場合や、TensorFlowやCaffeなどの分散フレームワークを実行する場合でもABCIの多様なアプリケーションには高度な管理ソフトウェアが必要です。 Docker、Singularity、その他のツールとともに、Altair Grid EngineはABCIのソフトウェアスタックで重要な役割を果たし、ワークロードが可能な限り効率的に実行されるようにします。
Altair Grid Engineは、GPUを利用したディープラーニング環境に独自の機能を提供します。
- GPUを表すために使用される抽象化であるAltair Grid Engineリソースマップ(RSMAP)を使用すると、GPU対応のワークロードをより効率的に管理して、使用率と生産性を向上させることができます。
- NVIDIAのDatacenter GPU Manager(DCGM)機能を利用することで、Altair Grid Engineの最新バージョンは、GPUの状態を考慮に入れてスケジューリングを決定し、タスクをより効率的にディスパッチして、深層学習ワークロードをより迅速に完了できます。
- Altair Grid EngineはDockerと統合され、コンテナー化されたワークロードのシームレスな管理をユーザーに提供します。 AltairはSingularityもサポートしているため、ABCIはコンテナーテクノロジーまたは同じクラスターにデプロイされたアプリケーションを実行できます。
このソフトウェアの組み合わせにより、ABCIはインフラストラクチャへの投資を最大限に活用できます。 Altair Grid Engineの最新リリースでは、計算タスクをCPUコアとGPUのさまざまな組み合わせにバインドして効率を向上させるための低レベルの詳細に多大な労力が費やされています。他のディープラーニングスーパーコンピュータと同様に、ABCIは、GPUコアがアイドル状態になるのを回避するための非GPUワークロードのスケジューリング、スイッチトポロジーとラック配置を考慮した方法での並列ジョブの配置、事前予約の使用など、Altair Grid Engineの革新から恩恵を受けます。優先ワークロードがスケジュールされた時間に実行されるようにします。
ABCIのような上位10位のスーパーコンピュータを運用している場合や、小規模のオンプレミスクラスターを運用している場合でも、GPUクラスターを実行すると、Altair Grid Engineのメリットを最大限に活用できます。 Pacific Teckは、オンプレミス、クラウド、またはハイブリッド環境で、ディープラーニングやその他の計算集中型のワークロードを管理するためのさまざまなソリューションを提供いたします。
Pacific Teckの役割
Pacific Teckは、システムインテグレーター(Fujitsu)と緊密に連携して、Altair Grid EngineおよびBeeONDの利点を理解しエンドユーザーに伝えました。 Pacific Teckの取り組みの一部であるAltair Grid EngineとBeeONDは、同様のプロジェクトTSUBAME3.0で利用され、エンドユーザーはこれらの要素の複製、また、Singularityにも関心を持っていました。 Pacific Teckはポストセールスにも関与しており、ベンダーとシステムインテグレーターの間の架け橋として機能しています。 また、Singularityコンテナーを管理するAltair Grid Engineを支援して、コンテナーでMPIジョブを実行しました。 BeeONDは計算ノードにNVMeから一時ファイルシステムを作成し、最大容量は約1PBです。 ある時点で使用されるサイズは、Altair Grid Engineによって開始されたときに決定されます。
BeeONDベンチマーク
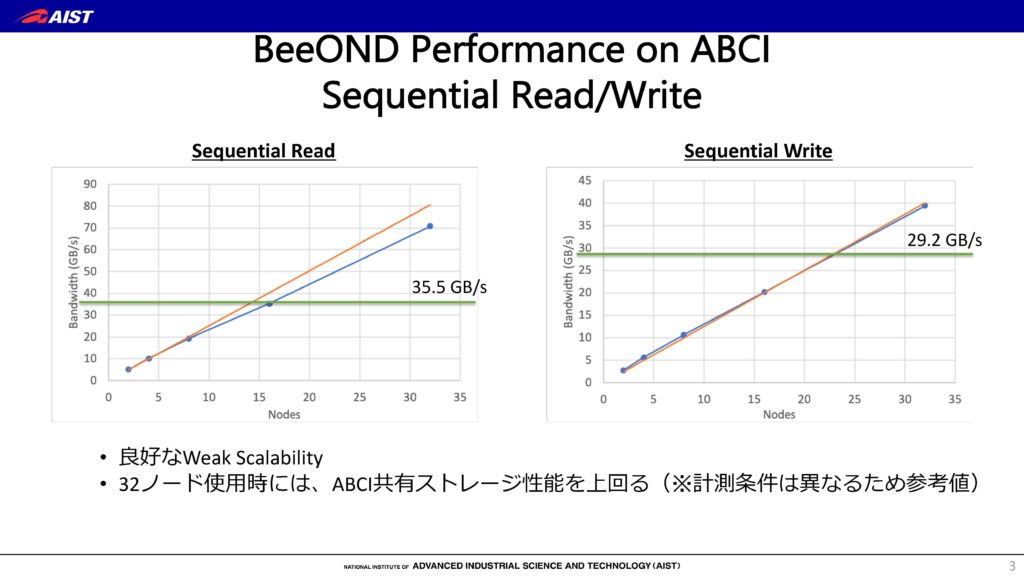
2019年2月1日に鹿児島で開催されたGfarm Workshop 2019でABCIとBeeONDのベンチマークが産総研から発表されました。産総研のABCI環境におけるBeeGFSの線形スケーラビリティを示す以下のスライドをご覧ください。


ジョブ管理システム
Altair Grid Engine
Altair Grid Engineは「ワークロードマネージャー」または「ジョブスケジューラ」と呼ばれ、複数のコンピュータで並列処理を行うクラスターコンピューティングで使用されます。

ストレージソフトウェア – パラレルファイルシステム
BeeOND
BeeONDはBeeGFS on Demandの略、BeeGFSを補完する製品です。他のファイルシステムでも使用可能です。 計算ジョブの実行中に計算ノードの内部SSD、NVMe、またはハードディスクを集約しパフォーマンスと容量を向上するために使用されます。パフォーマンス向上、スムーズなバーストバッファリングを提供します。計算ノード上にBeeGFSの1つまたは複数のインスタンスを作成し、「オンデマンド」で作成および破棄することで実現します。

HPC仮想コンテナシステム
SingularityPRO
Singularityはシンプルで安全なモバイルコンテナプラットフォームが欲しいという科学者の要望により開発されたLinux コンテナです。HPCだけにとどまらず他の分野でも広く活用されています。従来のHPCワークロードからAI、マシンラーニング(機械学習)、ディープラーニング、エンタープライズパフォーマンスコンピューティング(EPC)まで世界中で広く使用されています。