
cunoFS (Unleashing Object Storage)

What is cunoFS?
cunoFS is software that allows you to use your object storage as if it were mounted as a POSIX file system. It enables throughputs that are several to dozens of times higher than other services/tools, with benchmarks of over 50 Gbps per node and over 10 Tbps for multiple nodes.

Very simple to use
Workloads will be able to access the contents of the bucket as files, using a directory hierarchy. It allows user-level access and allows existing Linux applications to be used without modification.

Build the environment of your choice!
cunoFS integrates multi-cloud (Wasabi, Amazon AWS S3, Microsoft Azure Blob Storage, Google Cloud Storage, Oracle Cloud Infrastructure, etc.) and on-premise object storage into a single environment. cunoFS allows you to integrate on-premise object storage into a single environment. No application changes are required.
Use object storage as POSIX file system
cunoFS is compatible with Wasabi and other major object storage systems, and files stored in object storage using cunoFS are stored as one file and one object, so they can be read even in environments without cunoFS.
Simple and easy to use
There is no need to change the binaries of POSIX-compliant applications; cunoFS allows direct access to the files in the bucket.
You can use paths, user/group permissions, symbolic links, hard links, and POSIX ACLs to create the environment you expect.
As shown in the figure on the right, two access methods are available: URI-based and pathname-specified. However, some applications may not support URI-based access.

Unparalleled Performance
For example, simply launching cunoFS on an AWS EC2 instance will allow an application to access objects in the bucket directly as files or directories.
There is no need to stage using instance stores, EBS, or EFS/FSx. Notably, its performance outperforms similar tools such as S3FS, as well as individual storage solutions.
Even if you install CUNO on your system and connect it to cloud storage, you can use it at the maximum throughput according to your network performance.
| 50+ Gbps Read & Write | |
 | 0.75 ~ 6.6 Gbps Read 0.25 ~ 3.8 Gbps Write |
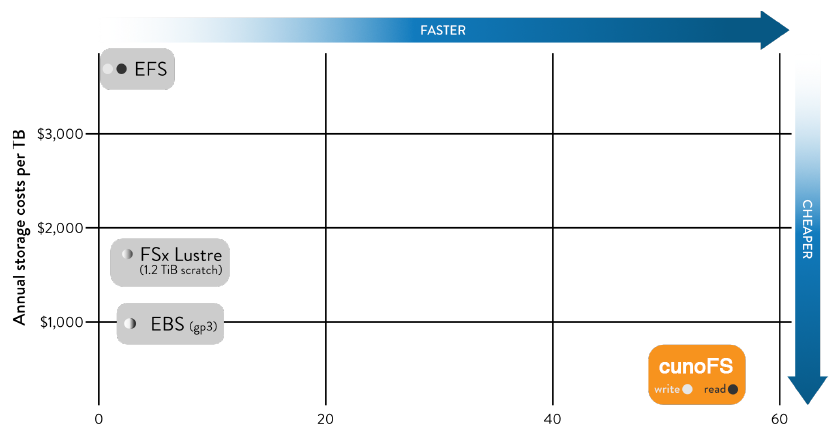
Tremendous cost savings
With cunoFS, file staging is no longer necessary. This also means that staging storage is no longer required.
Fast, high-capacity storage tends to be expensive. Eliminating staging by using cunoFS, which is fast with no overhead, can result in significant cost savings compared to building complex systems with other types of storage.
For example, when used on a c5n.18xlarge instance of AWS EC2, cunoFS can provide an environment with tens of times the throughput at a fraction of the price of EFS.
Product Features
- Object storage can be used directly as POSIX file system
- Provides unified namespace for cloud/on-premise object storage
- S3 compliant and integrates with leading object storage (tested environments: Wasabi Hot Cloud Storage, Amazon AWS S3, Microsoft Azure Blob Storage, Google Cloud Storage, Oracle Cloud Infrastructure)
- High transfer rate: up to 50+ Gbps for read/write to cloud object storage (for 1 node)
- Maintains high throughput even when accessed by a large number of nodes
- On-premise object storage read/write also accelerated
- One-stop shop for moving files between cloud providers with multiple simultaneous connections
- View and use objects as files
- Available for various operating systems: Linux, Mac OS (Docker Desktop for Mac), Windows (Windows Subsystem for Linux: WSL)
- User mode Linux client (FUSE not used or optionally FUSE mounted)
- POSIX access to objects: permissions/ACLs/symbolic links/hard links, etc.
- Random access read/write: no prior download required
- Runs in a containerized environment: Docker, Singularity compliant
- Can be run in a serverless environment
- Can be installed by non-root installations and standard Linux package managers (DEB, RPM, APK)
- Encryption in transit (FIPS 140-2 compliant)
- Full support of S3/GS/AZ access keys
- Import and manage user credentials for multiple accounts across various cloud providers and on-premise
- Supports access to S3 through IAM roles
Limitations
- There are the following restrictions on the maximum object size that can be used
- AWS S3: 5 TB
- Google Cloud Storage: 5 TB
- Azure Storage: 4.77 TB
- Python’s os.path.realpath (path) does not support URI-based access, such as xx://.
- Because cunoFS is a specification that works through a dynamic link library, some statically linked applications must change to dynamic linking or use Filesystem in Userspace (FUSE).
Performance and Features Comparison
cunoFS is much faster than other tools and services not only in transferring large files, but also in transferring small and large files.
Transfer performance (Large Files)
In reading and writing files of several GB, cunoFS achieves an astounding throughput that is several to dozens of times faster than other services and tools.

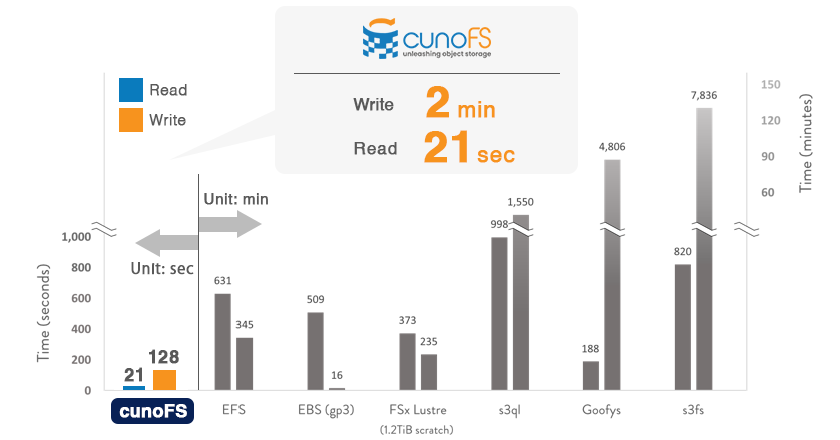
Transfer performance (Small Files)
High performance is achieved even when dealing with a large number of small files. For example, transferring 75,000 files of Linux kernel source code between EC2 and S3 using the cp command took several hours with other tools and services. In the cunoFS environment, however, it took only a little over 2 minutes to write and only 21 seconds to read.
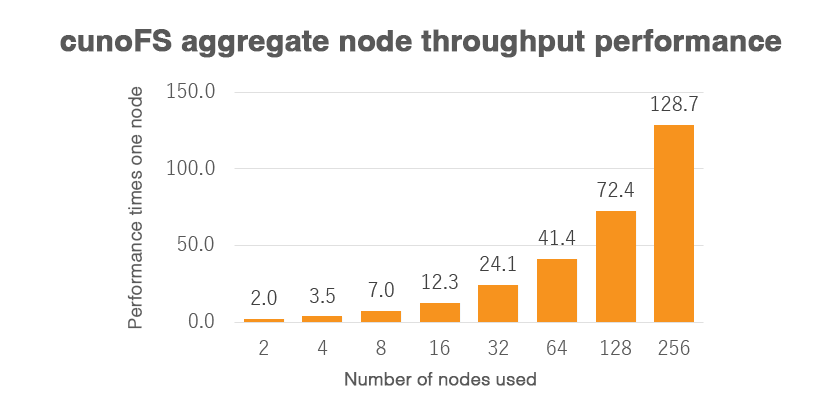
Throughput with aggregate nodes
cunoFS has high performance per node, but it can also aggregate multiple nodes to transfer data, and the throughput performance increases with the number of nodes. We recorded 10.9 Tbps using AWS EC2 c5n.18xlarge 256 nodes.
Performance and functionality comparison chart between cunoFS and other services/tools
Speed
 |  | EFS | EBS (gp3) | FSx Lustre (1.2TiB scratch) | s3ql | goofys | s3fs | |
|---|---|---|---|---|---|---|---|---|
| Throughput write (cp 5×32 GiB files) | 50+ Gbps | 50+ Gbps | 0.86 Gbps | 2.6 Gbps | 1.2 Gbps | 2.14 Gbps | 3.83 Gbps | 0.25 Gbps |
| Throughput read (cp 5×32 GiB files) | 50+ Gbps | 50+ Gbps | 2.1 Gbps | 2.8 Gbps | 2.1 Gbps | 1.45 Gbps | 6.62 Gbps | 0.75 Gbps |
| Read Linux kernel source from storage | 21 sec | 21 sec | 10 min 31 sec | 8 min 29 sec | 16 min 13 sec | 16 min 38 sec | 3 min 8 sec | 13 min 40 sec |
| Write Linux kernel source files to storage | 2 min 8 sec | 2 min 8 sec | 5 min 45 sec | 16 sec | 4 min 5 sec | 26 min | 1 hour 20 min | 2 hours 11 min |
Compatibility
| | EFS | EBS (gp3) | FSx Lustre (1.2TiB scratch) | s3ql | goofys | s3fs | |
|---|---|---|---|---|---|---|---|---|
| Access object as files | ✔︎ | ✔︎ | – | – | 1.2 Gbps | 2.14 Gbps | 3.83 Gbps | 0.25 Gbps |
| Access files as object | ✔︎ | ✔︎ | – | – | 2.1 Gbps | 1.45 Gbps | 6.62 Gbps | 0.75 Gbps |
| POSIX consistency domain | per user per node | cross user cross node | cross user cross node | single mount single node | cross user cross node | single mount single node | per mount per node | per mount per node |
| Atomic rename & hard links | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | – | – |
| Mode, UID/GID/permissions, timestamps | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | – | ✔︎ |
| POSIX ACL | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | – | ✔︎ |
| Random writes symlinks, fsync | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | – | ✔︎ |
| File locking | per user per node | cross user cross node | cross user cross node | single node | cross user cross node | – | – | – |
| POSIX permissions enforced at Object API | S3 | S3 | – | – | – | – | – | – |
Scalability
| | EFS | EBS (gp3) | FSx Lustre (1.2TiB scratch) | s3ql | goofys | s3fs | |
|---|---|---|---|---|---|---|---|---|
| Performance scales with nodes | ✔︎ | ✔︎ | – | – | by volume size | – | ✔︎ | ✔︎ |
| Multi-node support | weak consistency | ✔︎ | ✔︎ | ✔︎ | ✔︎ | – | weak consistency | weak consistency |
Use Cases

Big Data
Slow storage takes too much time to manipulate and operate on your data, and you cannot quickly gain critical insights from it. Whether you are using Hadoop, Spark, or another big data platform, running HBase, or simply want to visualize using RStudio and Shiny, cunoFS provides a fast environment. cunoFS provides a fast environment.

Life Sciences
Data requirements have become more intensive, with research requiring tens to hundreds of PBs of data. However, most life science software is slow and limited in its support of native objects or typically only supports POSIX file systems. cunoFS uses cloud storage to provide fast, POSIX-native storage.

HPC
With cunoFS, you can use inexpensive, high-capacity object storage directly and at high speed, which is a big plus in the HPC space. cunoFS enables direct and fast use of inexpensive, high-capacity object storage, making it a powerful tool in the HPC field.

Machine Learning
With the advent of machine learning, the performance requirements for data storage have become extremely high and one of the most important performance indicators, requiring not only high throughput performance to the GPU, but also the handling of many small files, TensorFlow, PyTorch, Dask, or any other framework, cunoFS provides a fast cloud storage environment.

Media
The media industry is grappling with multiple challenges in storage, production workflow management, distribution and streaming. Whether you are considering geographically distributed content production requiring globally redundant shared storage, storage performance challenges for Omniverse authoring, efficient Lambda transcoding or static/dynamic packaging, cunoFS will be of great help.
Contact
For any inquiries, please contact us via email at info@pacificteck.com .