
Altair Grid Engine(ジョブ管理システム)
Altair Grid Engine(AGE)とは
Altair Grid Engine(AGE)は、「ワークロードマネージャー」または「ジョブスケジューラ」と呼ばれることもあります。このソフトウェアは、複数のコンピューター(サーバー)を同時に使用して並列処理することが可能な「クラスターコンピューティング」の運用を容易することが可能です。
AGEは、作業の各セグメントに最適なリソースをユーザが意識することなく選択することにより、何千ものデータセンターのリソースを最適化する分散リソース管理システムです。
Pacific Teckは10年以上Altair Grid Engineのライセンスとサポートをアジア太平洋地域の数百のサイトに提供している実績があります。
リソースを最大限に活用
AGEは、他のスケジューラーよりも高度な方法である、GPUなどのリソースの配置場所をマップ情報として持ち、Linux cgroupを利用するResource Mapsと呼ばれる機能を持ちます。 Resource Mapsにより、相互接続、GPU、NVMe、メモリ、Intel CPUコアをノード内でマップおよびバインドし、他のソリューションよりもはるかに細かくリソースを制御できます。 1人のユーザーにリソースの多くのノードを提供したり、特定の時間、必要なだけグループ/ユーザー/ジョブが必要とするリソースのノードを分割し配分することが出来ます。 ノード内のCPU-GPU-メモリとインターコネクトの最適な組み合わせを使い、機能的にリソースを完全に活用します。 リソースは、ノードごとにコンテナー、ユーザー、またはジョブ毎にバインドすることができます。
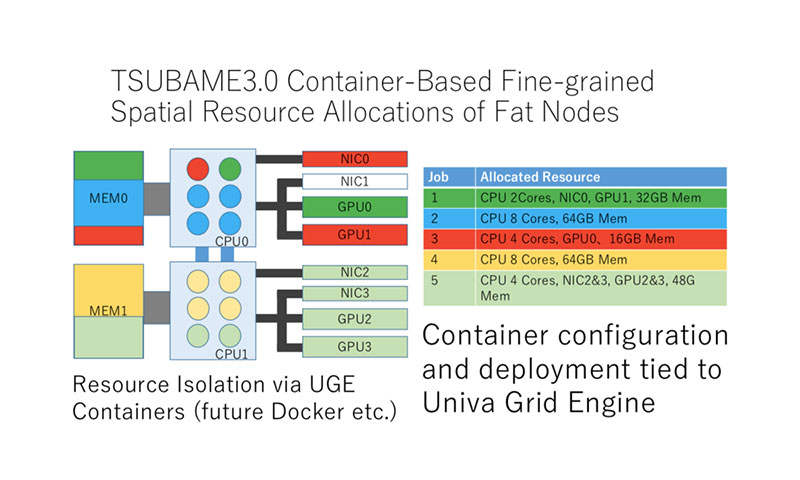
かつてないほどコンテナ管理が簡単に
多くのスケジューラーは、コンテナーの開始および停止の機能のみとなります。 ランタイム中にコンテナ内のジョブに起こることはブラックボックスとなりがちです。
Dockerを使用する場合、Altair Grid Engineは、コンテナの外側と内側にある1組ガイドを使用して、これらのジョブを完全に制御できます。 その結果、コンテナジョブは非コンテナジョブとまったく同じように実行できます。
Altair Grid EngineはSingularityPROやDockerのどちらのコンテナーでもMPIをサポートします。SingularityPROはMPI/HPCワークロードを念頭に設計されています。 Pacific TeckはSylabsと協力して、APACでSingularityの商用サポートを提供します。
BeeGFSおよびBeeONDによるデータパフォーマンスの最大化
Altair Grid EngineとBeeGFS・BeeONDは、TiTech(540ノード、ノードあたり4つのP100と4つのOPA HFIを持つ)とABCI(1088ノード、ノードあたり4つのV100と2つのEDRポートを持つ)にインストールされています。 Altair Grid EngineはBeeONDをキックオフし、使用するNVMeの数、使用するタイミング、およびジョブ終了後の処理を指示します。 計算ノードに含まれるNVMeを使用したオンデマンドバーストバッファーとなります。 AGEは、ユーザーが使用するBeeOND(NVMe)リソースの数を制限することも可能です。
ユースケース
マシーンラーニング(機械学習)
Altair Grid Engineは、世界最大の機械学習スーパーコンピューターで使用されています。 日本では、機械学習のリーダーであるAIST、理研AIP、およびTiTechがAltair Grid Engineを使用して、NVIDIA GPUを最大限に活用しています。
ライフサイエンス
Altair Grid Engineは、世界の主要な製薬会社で使用されており、医療および遺伝子研究ラボでデファクトとして使用されています。 日本では、東北大学医療メガバンク、国立遺伝学研究所、東京大学ヒトゲノムセンターなどで採用頂いています。
エンタープライズレベルのサポート
Pacific Teckは、Univa社時代から10年以上にわたりアジアの公式パートナーをしています。 Pacific TeckとAltair社は協業し、最高レベルのサポートと、堅牢なスケジューラを提供します。
NEWS
使用実績
- 理化学研究所 革新知能統合研究センター(AIP) – 日本
- ABCI / AIST(産業技術総合研究所) – 日本
- 京都大学 – 日本
- 弘前大学 – 日本
- TSUBAME3.0 / 東京工業大学 – 日本
- ToMMo(東北メディカルバンク機構) / 東北大学 – 日本
- 東北大学 流体科学研究所 / 東北大学 – 日本
- ヒトゲノム解析センター(HGC) / 東京大学 – 日本
- 国立遺伝学研究所(NIG) – 日本
- 農業生物系特定産業技術研究機構(NARO) – 日本
- 株式会社デンソー – 日本
- ホンダエンジニアリング株式会社 – 日本
- かずさDNA研究所 – 日本
- 国立がん研究センター – 日本
- 台湾ナショナルスーパーコンピュータセンター (NCHC) – 台湾
- A*STAR GIS(シンガポール科学技術研究庁ゲノム研究所) – シンガポール
ベンチマーク・その他発表
- 2020/11/18 | AltairがArmベースの富士通スーパーコンピューターPRIMEHPC FX700システムのサポートを発表
- 2020/9/14 | Altair、Univa社を買収
Altair Grid Engine関連動画

データシート・リリースノート

Altair Grid Engineお見積もり・お問い合わせ
お客様のご要望に合わせてカスタマイズが可能です。システム構成などお気軽にご相談ください。
お問い合わせは info@pacificteck.com までメールにてご連絡ください。