
什么是AGE
Altair Grid Engine (AGE)是 Altair 的旗舰产品,通常被称为“工作负载管理”或“作业调度系统”。 这些类型的软件产品促进了“集群计算”,这意味着同时使用多台计算机(服务器)来处理信息。
Altair Grid Engine 是领先的分布式资源管理系统,它通过透明地选择最适合每个工作段的资源来优化数千个数据中心的资源。
Pacific Teck 已向亚太地区数百个用户提供了Altair Grid Engine的授权和支持。
为什么使用AGE
Altair Grid Engine 是市场上最先进且支持最完善的作业调度程序。 它在资源利用率、与容器解决方案的紧密集成以及环境规模和支持的作业数量的百亿亿级可扩展性方面无与伦比。
Altair Grid Engine 具有在节点内资源的映射高级功能,包括 GPU、CPU、内存和网络。一旦 映射后,Altair Grid Engine 可以按作业分配这些资源。这意味着当用户只需要一个节点的一部分资源来完成他们的工作时,他们就可以得到他们所需的资源即可。 如果必须保留整个节点,部分资源就会被闲置,无法被其他人使用,因此这些资源也就被浪费了。
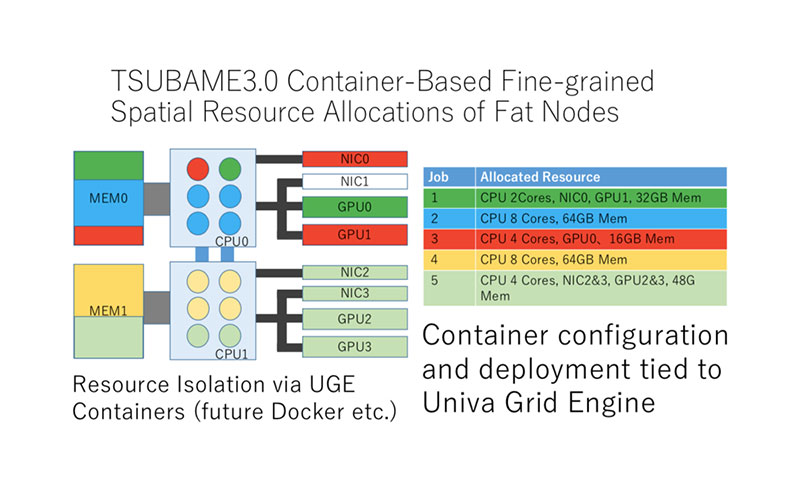
更加充分利用您的资源
Altair 开发了一项名为 Resource Maps 的功能,该功能具有 GPU 等资源定位的图,比其他调度系统更先进的方式利用 Linux cgroup。 该功能能够在比其他解决方案更精细的级别控制资源:网络、GPU、NVMe、内存、英特尔 CPU 内核可以在一个节点内映射和绑定在一起。
这样做的好处是,与其将一个非常多“资源”的节点分配给一个用户,不如将该节点的“资源”拆分为组/用户/作业在给定时间内的所需。 这在功能上有助于更加的充分利用资源,并在使用节点中的资源时使用最佳CPU- GPU-Memory和网络互连的整合。 资源也可以绑定到每个节点的多个容器、用户或作业中。
比以往更加容易的管理容器
许多调度程序只具备启动和停止容器的能力。 在运行时容器内的作业发生了什么是一个不公开的黑匣子。
使用 Docker 时,Altair Grid Engine 使用一对位于容器内外的shepherd来完全控制这些作业。 这样容器作业可以像非容器作业一样运行。
Singularity Pro 和带有 Altair Grid Engine 的 Docker 都支持容器的MPI,不过 Singularity Pro 在设计之初特别考虑了 MPI/HPC 工作负载。
Pacific Teck 还与 Sylabs 合作,为 Singularity 在亚太地区提供商业支持。
最大化BeeGFS 和 BeeOND的性能
Altair Grid Engine 和 BeeGFS/BeeOND 在TiTech( 540 Nodes with 4 P100 and 4 OPA HFIs per node ) 和 ABCI (1088 Nodes with 4 V100 and 2 EDR ports per node)等项目中解决用户所需。 Altair Grid Engine 提交作业运行时启动 BeeOND ,并告诉BeeOND要使用多少 NVMe、何时使用以及工作完成后要做什么。 这是使用计算节点中实际使用的 NVMe 来作为作业系统的突发缓冲。
Altair Grid Engine 还可以限制用户使用一定数量的 BeeOND (NVMe) 资源。
应用案例
机器学习
Altair Grid Engine 用于世界上最大的机器学习超级计算机。 在日本,机器学习领导者 AIST、RIKEN AIP 和 TiTech 正在使用 Altair Grid Engine 来最大限度地利用 NVIDIA GPU 节点。
生命科学
Altair Grid Engine 被多数世界上主要的制药公司所使用,并且已经成为了医学和基因研究实验室的主导力量。 在日本,一些最大的机构使用 Altair Grid Engine,例如 Tohoku University Medical Megabank、国立遗传学研究所和东京大学的人类基因组中心等。
企业级的支持
Pacific Teck 成为 Altair 在亚洲的官方合作伙伴已超过 10 年。 Pacific Teck 和 Altair 携手合作,提供任何可用作业调度程序的一流支持和最强大的路线图。
案例学习
- RIKEN Center for Advanced Intelligence Project(AIP) – Japan
- ABCI / National Institute of Advanced Industrial Science and Technology(AIST) – Japan
- Kyoto University – Japan
- Hirosaki University – Japan
- TSUBAME3.0 / Titech – Japan
- Tohoku Medical Megabank Organization(ToMMo) / Tohoku University – Japan
- Institute of Fluid Science, Tohoku University – Japan
- The Institute of medical science(HGC), The University of Tokyo – Japan
- National Institute of Genetics(NIG) – Japan
- The National Agriculture and Food Research Organization(NARO) – Japan
- DENSO CORPORATION – Japan
- Honda Engineering – Japan
- Kazusa DNA Research Institute – Japan
- National Cancer Center – Japan
- National Center for High-Performance Computing – Taiwan
- A*STAR the Genome Institute of Singapore(GIS) – Singapore
Benchmark和其他
新闻
- Altair announces support for Arm-based Fujitsu Supercomputer PRIMEHPC FX700 systems
- Altair Acquires Univa
联系我们
我们可以根据您的需要对其进行定制。 有关系统配置,请随时与我们联系。